
- par
- Watilin
- le
- 10/08/2012 à 12:15
Le DOM
![]() À notre époque, où l’évolution des technologies du web est exponentielle, le nombre de développeurs ne connaissant pas le DOM (voire même son nom) est toujours horriblement grand. Cela implique une quantité déraisonnable de sites mal faits sur la toile…
À notre époque, où l’évolution des technologies du web est exponentielle, le nombre de développeurs ne connaissant pas le DOM (voire même son nom) est toujours horriblement grand. Cela implique une quantité déraisonnable de sites mal faits sur la toile…
Mal faits, comment ça ? Dans le cas général, le développeur qui ne connaît rien au DOM ne se soucie pas non plus de tout ces petits détails
que sont le balisage sémantique, la modularisation du code, et autres ennuyeusetés
dont je ne parlerai pas dans cet article. Je parlerai ici de l’utilité du DOM html – il y a d’autres DOM – seul outil fiable et portable voué à la manipulation des éléments d’une page web.
Qu’est-ce que le DOM ?
DOM signifie Document Object Model. Il s’agit d’une arborescence représentant la hiérarchie des éléments d’un document, d’où son nom. Dans le cas qui nous intéresse, le document est une page web, et ses éléments sont – le plus souvent – les balises.
Le DOM est conçu pour être utilisé avec n’importe quel langage de programmation. Ici, nous travaillons sur des pages web, l’outil est donc tout indiqué : nous utiliserons JavaScript.
Le W3C, père du DOM
Vous savez sans doute que le bon fonctionnement de JavaScript, et même des styles CSS délicats, dépend fortement du navigateur utilisé, en particulier avec MSIE… Le W3C est une communauté internationale qui cherche à rendre le web entièrement standardisé.
Pour édifier des standards, ses différentes équipes de travail publient
ce qu’ils nomment des recommandations
sous forme très structurée, souvent un schéma DTD ou XML. Si la curiosité vous pique, vous pouvez toujours jeter un œil aux recommandations du DOM. Mais pas de panique, vous n’aurez pas tout de suite besoin de vous en servir. C’est une documentation pointue censée vous répondre lorsque vous cherchez une info précise…
De l’utilité du DOM HTML
Le DOM, pour résumer ce que j’ai dit, décrit précisément l’arborescence d’une page web. Là où il va se montrer utile, c’est qu’il est, grâce au travail du navigateur, directement relié à JavaScript. En réalité, c’est le seul moyen rigoureux de manipuler avec JavaScript les éléments de sa page !
Techniquement, ça se présente ainsi : le navigateur, en analysant la page, met à disposition sous forme de code JavaScript l’ensemble des possibilités du DOM. Bien sûr, cela va dépendre du navigateur… Comme toujours, MSIE va faire chier son monde pas mal.
On passe aux choses sérieuses
Jargon technique
Voici les pièces indispensables pour bien comprendre tout document parlant du DOM. Pour commencer, il faut visualiser le fait que le DOM est un arbre d’objets JavaScript représentant les éléments du document.
- Nœud
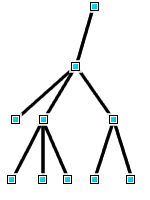 Un nœud correspond à un point de l’arbre où plusieurs branches sont reliées, ou bien à l’extrémité d’une branche. En html, il va s’agir le plus souvent des balises, mais aussi des portions de texte seul (on parle de nœud texte) et des attributs.
Un nœud correspond à un point de l’arbre où plusieurs branches sont reliées, ou bien à l’extrémité d’une branche. En html, il va s’agir le plus souvent des balises, mais aussi des portions de texte seul (on parle de nœud texte) et des attributs.
- Racine, parents, enfants
- Là c’est assez intuitif : le nœud racine est celui situé tout en haut de l’arbre ; les nœuds situés immédiatement en-dessous seront ses enfants, qui sont à leur tour parents des éventuels nœuds se trouvant plus bas, etc.
- Interface
- Comme je l’ai dit plus haut, le DOM fournit un modèle JavaScript des éléments de la page. Les nœuds sont donc des objets JavaScript, qui, comme tout objet qui se respecte, possèdent des propriétés (des champs et des méthodes).
Une interface est une sorte depaquet
de propriétés qui vont se rajouter à un nœud suivant son type. Par exemple, un attribut recevra l’interfaceAttr. Je dirai parfois que tel objet hérite de telle interface.
NB : tous les nœuds sont d’office affublés de l’interfaceNode!
Pour bien fixer les idées, commençons par examiner l’arbre DOM d’un document assez simple. Le code HTML est le suivant :
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="fr-FR" lang="fr-FR">
<head>
<meta http-equiv="content-type" content="text/html; charset=utf-8" />
<title>Document assez simple</title>
</head>
<body>
<h1>Document assez simple</h1>
<p>Ceci est un document simple.</p>
</body>
</html>Pas de panique si vous ne comprenez pas tout : la déclaration DOCTYPE est assez impressionnante si on ne connaît pas, mais elle est toujours la même ; les attributs bizarres de la balise html sont de petites obligations, du fait qu’on est en mode xHTML. Pour vous convaincre que ce document est simple, regardez le résultat !
Quelques-uns des navigateurs récents (et pas trop mauvais) comportent un inspecteur DOM. Je me sers de celui de Firefox pour cet exemple.
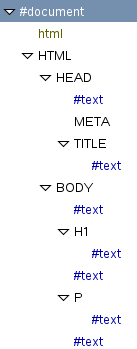 Voici l’arbre DOM, entièrement déroulé, de notre page d’exemple.
Quelques remarques importantes :
Voici l’arbre DOM, entièrement déroulé, de notre page d’exemple.
Quelques remarques importantes :
#documentsera toujours le nœud racine de votre document. Ça ne manque pas de logique.- Le
htmlcoloré qui apparaît à la 2me ligne est un cas assez exotique (à vrai dire, on s’en fiche complètement) : il correspond à l’instruction donnée par la déclaration DOCTYPE, qui définit l’élémenthtmlcomme l’élément racine de la page (pour le HTML, pas pour le DOM). J’espère que je n’ai perdu personne… - Notez que le texte des balises n’est pas vraiment contenu dans ces balises : ce sont en réalité des nœuds de type
#text, enfants du nœud balise correspondant. - Qu’est-ce que c’est que tous ces nœuds
#text? Normalement, il ne devrait y en avoir que pourtitle,h1etp? Ils correspondent en fait aux espaces de toute sorte (indentations, sauts de ligne) dans le code source. Le navigateur n’en tient pas compte, mais ils ne sont pas effacés pour autant et ils se retrouvent dans le DOM. Il va falloir apprendre à ne pas les oublier quand on manipule le DOM ! - Les noms de balises sont en majuscules. La tendance aujourd’hui est plutôt aux minuscules, c’est même obligatoire en xHTML, alors pourquoi ? En réalité, je ne sais pas vraiment pourquoi, c’est une histoire de
noms canoniques
… Quoiqu’il en soit, quand vous aurez besoin d’utiliser des noms de balises dans votre JavaScript, préférez utiliser les noms en minuscules : vous serez sûrs de n’avoir aucun souci. - Les attributs sont aussi des nœuds, mais par commodité l’inspecteur ne les affiche pas directement. Ils s’afficheront à droite quand vous sélectionnerez un nœud.
Dernier détail, si vous n’êtes pas familier avec la syntaxe objet de
JavaScript (et de nombreux autres langages objet dont Java, la famille C, ruby, etc.) : pour accéder à la propriété prop de l’objet
obj, vous devez utiliser l’opérateur point (.), comme ceci : obj.prop
Il en va de même avec les méthodes. Vous allez vous habituer très vite, les exemples sont légions dans ce qui suit !
Les interfaces
L’interface Node, premier acte : généalogie
Omniprésente, Node sera, en toute logique, une des interfaces les plus utilisées. Elle vous fournit le moyen de se déplacer dans l’arbre, vers les parents, les voisins ou les enfants du nœud courant. Elle permet également de modifier l’arbre : ajout, suppression, remplacement de nœuds.
Pour l’anecdote, sachez que Node fournit également des propriétés générales, nodeName, nodeType, nodeValue ou encore attributes, mais vous verrez qu’en pratique on ne les utilise jamais : elles ont leurs équivalents dans les interfaces Text ou Element. Allez hop, c’est parti…
| Propriété | Schéma | Description |
| parentNode |  |
remonte d’un étage : fournit le nœud père. Si le nœud est #Document ou n’est pas rattaché au DOM de la page (oui oui, ça existe), vous obtiendrez null. |
|---|---|---|
| childNodes |  |
C’est le contraire : il fournit les nœuds enfants. Comme ils peuvent être plusieurs, childNodes renvoie un objet ressemblant à un tableau, mais qui n’en est pas vraiment un. J’appellerai ces objets des collections. Les collections héritent de l’interface NodeList, dont je parle juste après… |
| firstChild |  |
Bien pratique, firstChild fournit le premier élément fils. Attention toutefois aux nœuds #text inattendus… |
| lastChild |  |
Vous l’aurez deviné, il fournit le dernier élément fils. Si l’élément courant n’a qu’un seul nœud fils, on a donc firstChild ==
lastChild ! |
| previousSibling |  |
On reste sur le même niveau : previousSibling fournit le voisin précédent (j’entends par voisins deux nœuds qui ont le même père). Bien sûr, si vous êtes sur le premier élément, vous vous mangerez un null… |
| nextSibling |  |
Évidemment, le voisin suivant. Même remarque si vous êtes sur le dernier élément. |
Toujours dans cette idée de relations de parenté, Node propose deux petites méthodes qui peuvent être utiles, des prédicats à utiliser dans vos tests :
| Méthode | Description |
| hasAttributes() | Renvoie true si le nœud possède au moins un attribut. |
|---|---|
| hasChildNodes() | Renvoie true si le nœud possède au moins un fils. C’est un équivalent, plus élégant, du test childNodes.length > 0. |
On a besoin de connaître NodeList avant de faire quelques exemples, histoire de voir childNodes en même temps que le reste.
L’interface NodeList
NodeList est souvent utilisée, car elle est le type des objets
renvoyés par childNodes ou les méthodes comme getElementsByTagName() de l’interface Document. Il est important de ne pas la confondre avec un tableau, car la très grande partie des propriétés et méthodes de tableaux ne s’y applique pas (par exemple, les méthodes map, forEach, pop, etc.). En réalité, elle ne présente qu’une seule propriété et une seule méthode !
| Propriété | Description |
| length | Longueur de la collection. Autrement dit, le nombre d’éléments. |
|---|
| Méthode | Description |
| item(i) | Renvoie l’objet de position i de la collection. C’est l’équivalent de tableau[i], et le comportement est le même : le premier est à la position 0, le dernier à length - 1. |
|---|
Notez que le DOM étant profondément ancré dans le langage JavaScript, vous aurez parfois accès à des raccourcis pratiques. C’est le cas ici : plutôt qu’utiliser collection.item(i), JavaScript vous offre le raccourci collection[i], comme pour les tableaux.
On y va pour les exemples ! Considérons le fragment HTML suivant :
<div id="conteneur">
<h1 id="titre">Un gros titre…</h1>
<ul id="liste">
<li id="riri">Riri</li>
<li id="fifi">Fifi</li>
<li id="loulou">Loulou</li>
</ul>
</div>J’ai mis des id partout afin de pouvoir récupérer facilement les éléments, via la méthode getElementById que vous connaissez tous et qui appartient en fait à l’interface Document. Notez au passage que je ferme soigneusement toutes mes balises, y compris les li et les p. C’est important, car si vous ne le faites pas vous risquez d’avoir un DOM bizarrement construit, même si la page s’affiche correctement.
Dans tous les exemples qui suivent, je m’efforcerai d’écrire du code JavaScript valide afin que vous puissiez facilement le vérifier (si vous ne me croyez pas sur parole ^^) en le copiant / collant. Je mets donc le résultat d’une instruction en fin de ligne, en commentaire.
// Je commence par récupérer tous les éléments :
var conteneur = document.getElementById('conteneur');
var titre = document.getElementById('titre');
var liste = document.getElementById('liste');
var riri = document.getElementById('riri');
var fifi = document.getElementById('fifi');
var loulou = document.getElementById('loulou');
// Voici quelques comparaisons :
conteneur.firstChild == titre; // false ! Il y a un nœud #text avant…
riri.parentNode == liste; // true
fifi.nextSibling.nextSibling == loulou; // true
conteneur.childNodes.item(4) == liste; // true
liste.childNodes.length == 7; // true : il y a 4 nœuds #text.
// Voyons les prédicats :
loulou.hasAttributes(); // true à cause de l’id
liste.hasChildNodes(); // trueL’interface Document
Document est l’autre interface fondamentale du DOM. C’est elle qui
vous permet d’obtenir un nœud, en le récupérant dans la page ou en le créant
carrément. Pour utiliser cette interface, il faut appeler un objet fourni par
JavaScript, l’objet document (avec un d minuscule).
L’interface Document possède quelques propriétés, dont documentElement qui renvoie l’élément racine de la page, mais
aucune n’est vraiment intéressante quand on est un développeur sain d’esprit. Passons aux méthodes :
| Méthode | Description |
| createElement(nomBalise) | Adoptez-la ! C’est l’unique méthode standard pour créer un nœud. Le nœud fraîchement créé vous sera retourné par la fonction, pour vous permettre de le stocker dans une variable avant de lui faire subir d’autres traitements, comme lui donner des enfants ou le rattacher à la page. |
|---|---|
| createTextNode(texte) | Les nœuds #text n’étant pas des balises, il fallait bien une méthode permettant d’en créer. Vous passez une chaîne à cette fonction, et elle vous renvoie un nœud #text à garder en mémoire. |
| getElementsByTagName(nomBalise) | Renvoie une NodeList contenant toutes les balises de la page correspondant au nom demandé. S’il n’y en a pas, vous aurez une liste vide… |
| getElementById(id) | Celle-là, tout le monde la connaît. Elle récupère l’unique élément portant l’id demandé. Si cet élément n’est pas unique, c’est que vous avez mal construit / modifié votre page, et dans ce cas, nul ne peut prévoir quel élément vous allez vraiment récupérer… |
| getElementsByName(name) | C’est une vieillerie, mais elle n’est pas obsolète ! Elle vous permet de récupérer tous les éléments portant le même nom (ayant la même valeur dans l’attribut name). Utile pour manipuler les éléments de formulaires. |
Petite erreur de débutant (je sais de quoi je parle, je l’ai faite) : toutes ces méthodes demandent qu’on leur passe un argument sous forme de chaîne. Il faut donc faire un peu attention : si vous voulez passer une chaîne directement, ne pas oublier les guillemets, sinon JavaScript pensera que vous essayez de passer une variable. À l’inverse, si vous voulez lui passer une variable contenant une chaîne, ne mettez pas de guillemets !
Un petit exemple va clarifier les choses :
// passage de chaîne directement :
var paragraphe = document.createElement('p');
var lesDivs = document.getElementsByTagName('div');
// passage via variable :
var monId = 'boite';
var maBoite = document.getElementById(monId);
var blabla = 'Il était une fois…';
var noeudTexte = document.createTextNode(blabla);C’est une simple question de clarté du code : on préfère que la série
d’arguments passés à une fonction soit courte. Les variables sont donc
naturellement utilisées pour créer les nœuds #text comme je viens de le faire, car avouez que :
var grosTexte = 'Frui enim habitos esse si securitatem habitos si pro implicari.';
var joli = document.createTextNode(grosTexte);est quand même plus lisible que :
var moche = document.createTextNode('Frui enim habitos esse si securitatem habitos si pro implicari.');L’interface Node, second acte : faites des enfants !
Retour sur Node, car je ne vous avais pas tout dit ! Maintenant que vous savez créer des élements, je vais vous montrer comment les assembler (comme des légos quoi).
L’assemblage des nœuds se fait grâce à d’autres méthodes de Node, que je vous présente dans le tableau suivant. Je précise que quand je parle de l’élément courant, il s’agit de l’élément sur lequel on appelle la méthode, par exemple dans :
bertrand.appendChild(gerard);L’élément courant est bertrand.
| Méthode | Description |
| appendChild(nœud) | le paramètre nœud doit être un nœud réglementaire, c.-à-d. que vous devez l’avoir créé ou récupéré au préalable. La fonction va rajouter le nœud à l’élément courant, après les autres fils éventuels. |
|---|---|
| cloneNode(booléen) | Renvoie une copie de l’élément courant, profonde si vous passez true, superficielle si vous passez false. La copie profonde clone l’élément et tous ses descendants (fils, petits-fils, etc.), tandis que la copie superficielle ne clone que l’élément lui-même (style coquille vide). |
| insertBefore(nouveau, ref) | insère le nœud nouveau parmi les fils de l’élément courant juste avant le nœud ref. Attention : si ref ne convient pas, vous ramassez une DOMException qui, comme toutes les exceptions, est une erreur fatale : votre script s’arrêtera là. |
| removeChild(nœud) | retire nœud des enfants de l’élément courant. Le nœud fraîchement retiré vous est retourné par removeChild, afin de le garder en mémoire pour d’autres traitements (l’envoyer à la DDASS par exemple). Ici aussi, attention aux exceptions. |
| replaceChild(nœud, cible) | Remplace cible par nœud. On a vite fait de se tromper dans l’ordre des arguments avec cette méthode… |
J’attire votre attention sur un détail important : les méthodes
appendChild(), insertBefore() et
replaceChild() sont parfois sournoises. Si vous utilisez un nœud qui était déjà présent ailleurs dans le document, cela produira un déplacement : il sera retiré à son emplacement précédent avant d’être introduit là où vous l’avez demandé. C’est appréciable si on veut justement déplacer le nœud, mais si on ne veut pas ?
Ce problème survient lorsqu’on utilise des nœuds récupérés avec les méthodes de Document. Pour éviter ça, clonez le nœud ! Vous obtenez une copie du nœud, certes exactement égale à l’original, mais ce n’est pas le même objet. Vous pouvez donc l’insérer sans risque.
À présent, quelques exemples :
// création d’un fragment HTML « <p>Bonjour.</p> »
var p = document.createElement('p');
var texte = 'Bonjour.';
var noeudTexte = document.createTextNode(texte);
p.appendChild(noeudTexte);
// ajout du nœud en haut de la page
document.body.insertBefore(p, document.body.firstChild);
// finalement, j’ai changé d’avis…
document.body.removeChild(p);L’interface Element
Element est une extension de Node qui va s’appliquer aux balises. Les attributs et les nœuds #text ne font donc pas partie de la fête. Sa propriété tagName peut parfois être utile. Ses méthodes permettent de manipuler de manière générique les attributs de l’élément :
| Méthode | Description |
| getAttribute(x) | Recherche l’attribut x parmi les attributs de l’élément courant, et vous renvoie sa valeur. S’il n’existe pas, la méthode vous renvoie la valeur par défaut s’il y en a une, ou bien une chaîne vide. |
|---|---|
| setAttribute(x, val) | Permet de changer la valeur de l’attribut x en val. Si vous dérapez, par exemple en modifiant un attribut que la balise n’est pas censée avoir, ou qui est protégé en écriture, ça provoquera une DOMException. En réalité, cette méthode est peu utilisée, vous verrez pourquoi un peu plus tard. |
| hasAttribute(x) | Renvoie true si la balise possède bien l’attribut
x. Cette méthode aurait pu être utile si elle marchait aussi sous IE… à la place, utilisez un test avec l’opérateur in (voir exemples). |
Les arguments de ces trois méthodes étant des noms ou des valeurs d’attribut, ils sont de type chaîne de caractères. Rien de bien méchant ici, inutile de s’attarder sur des exemples…
Dans l’interface Element, on retrouve également la méthode
getElementsByTagName(), déjà présente dans Document. La différence est qu’ici, elle est appelée depuis un élément particulier. Elle va rechercher les balises concernées parmi les enfants de l’élément courant, et pas dans tout le document.
L’interface Text
Cette interface, dont héritent les nœuds #text, possède un certain nombre de propriétés assez étranges, dont je ne me suis jamais servi, c’est pourquoi j’estime que ce n’est pas très grave si je n’en parle pas ici… Deux d’entre elles ont retenu mon attention. La première est length, qui permet de récupérer la longueur du texte, par exemple :
var phrase = 'Je mange un pain au raisin.';
var noeudPhrase = document.createTextNode(phrase);
noeudPhrase.length; // = 27C’est plus rapide si on n’a pas besoin de manipuler le texte lui-même. Dans le cas contraire, on peut passer par la propriété nodeValue de l’interface Node (que vous connaissez maitenant), ou bien par la propriété data de Text. Je trouve plus lisible d’utiliser data, car on sait tout de suite qu’on a affaire à un nœud #text en lisant le code.
// cette comparaison est vraie :
noeudPhrase.data == phrase;Le monde merveilleux du DOM HTML
Entrons à présent dans cet univers onirique rempli de féériques interfaces vouées spécialement au HTML pour nous faciliter la vie !
L’interface HTMLDocument
Commençons par un fait d’ordre presque anecdotique. HTMLDocument est une interface qui va étendre encore un peu l’objet document fourni par JavaScript. Dans un souci de compatibilité avec de vieux sites, elle a gardé de vieux oripeaux devenus obsolètes avec le temps, que je citerai pour mémoire. Il y a là write() et writeln() datant de la préhistoire
du DOM, qui s’utilisent conjoitement avec open() et close() pour manipuler la page comme un stream du langage C (le choix parfait si vous êtes masochiste) ; les propriétés cookie et referrer qui ne devraient pas avoir leur place côté client, ainsi que domain et URL qui ne servent carrément à rien ! Restent les anciens (mais toujours valides) moyens de récupérer des collections : images,
applets, links, forms et
anchors.
Finalement, seules 2 propriétés de cette interface retiennent mon attention :
| Propriété | Description |
| body | Un raccourci pour sélectionner le body, bon à connaître. |
|---|---|
| title | Raccourci pour accéder au titre de la page. Comme celui-ci reste visible dans la barre des tâches quand le navigateur est réduit, il peut être utile de le modifier pour signaler qu’un chargement est terminé, par exemple. |
Enfin, j’ai choisi de mettre à part la méthode getElementsByName(), qui n’est pas désuète mais n’est plus vraiment utile, étant donné qu’on peut tout manipuler avec les id. N’oubliez pas que l’attribut name n’est presque plus autorisé en xHTML Strict : les seules exceptions concernent les maps et les éléments de formulaires.
Commentaires
Tres Bon article!!
Merci.
Très clair, merci!
Page :